

Dibsic, the Chinese artificial intelligence laboratory, which recently assumed the industry assumptions on the costs of developing the sector, released a new family of open source artificial intelligence models that surpass the Dall-E 3 of Openai over the main standards.
His name is Yanos ProThe model ranges between one billion (very small) to 7 billion parameters (near the SD 3.5L size) and is available for immediate downloading on machine learning and data science Lugingface.
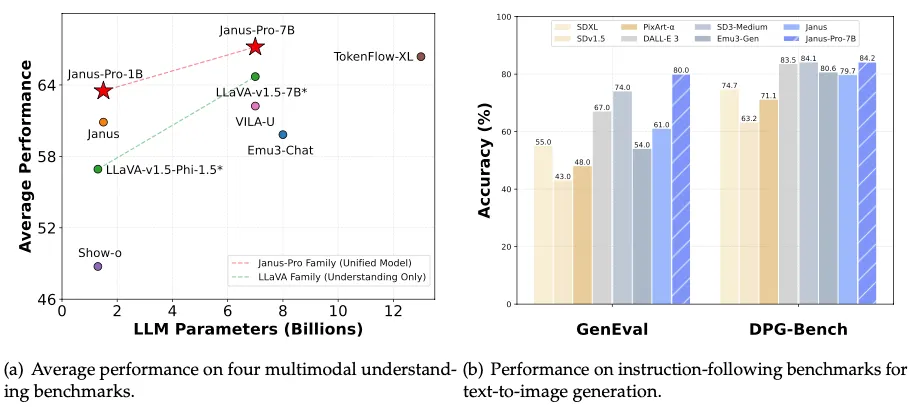
The largest version, Janus Pro 7B, not only beat the Dall-E 3 from Openai, but also other leading models such as Pixart-Alpha, EMU3-Gen and SDXL on GENEVAL and DPG-BenC industry standards. subscriber By Deepseek ai.
Its release comes a few days after Dibsic has the headlines with the headlines with R1 language modelThat match the GPT-4 capabilities while it costs only $ 5 million to develop-Detail hot discussion About the current situation of the artificial intelligence industry.
The Chinese startup product also led to fears at the sector level that can raise their occupants and expel the growth path to the main chips manufacturer NVIDIA, which has suffered from one largest day one day Loss of the maximum market On Monday date.
Deepseek's Janus Pro Model uses what the company calls a "new automatic pressure frame" that dismantles visual coding in separate paths while maintaining a single uniform transformer structure.
This design allows the model to analyze images and create images with a resolution of 768 x 768.
"Janus Pro exceeds the previous uniform and matches or exceeds the performance of the mission models," he claimed Deepseek there. Document launch. "Simplicity, high flexibility and the effectiveness of Janus Pro makes it a strong candidate for the unified multimedia models of the next generation."
Unlike Deepseek R1, the company did not publish a full white paper on the form but it released its technical documents and Make the model available for immediate download free-The eradication of its practice of open source versions that contrast sharply with the closed and ownership approach to the American technology giants.
So, what is our ruling? Well, the model is very versatile.
However, you don't expect to replace any of the most specialized models you love. The text can be born, analyze images, and create images, but when you incite the models that only do one of these things, at best, they are equal.
Form test
Note that there is no immediate way to use the traditional user interface to run - COMFY, A1111, focus, and draw things that are not compatible with it now. This means that it is somewhat in practice to run the model locally and requires text orders at a station.
However, some HugGinFace users have created distances to try the model. Dibsic official area Not available, so we recommend using Neurosinko's Free space for Yanos 7b experience.
Be aware of what you do, because some addresses may be misleading. For example, and The area run by AP123 He says he runs Janus Pro 7B, but instead runs Janus Pro 1.5B - which may end up making you lose a lot of free time to test the model and get bad results. Trust us: We know because it happened to us.
Optical understanding
The model is good in visual understanding and can describe the elements in the image accurately.
Show a good space awareness and the relationship between different things.
It is also more accurate than LLAVA-the most common open source vision form-for example, to provide more accurate descriptions of the viewer and interact with the user based on visual claims.
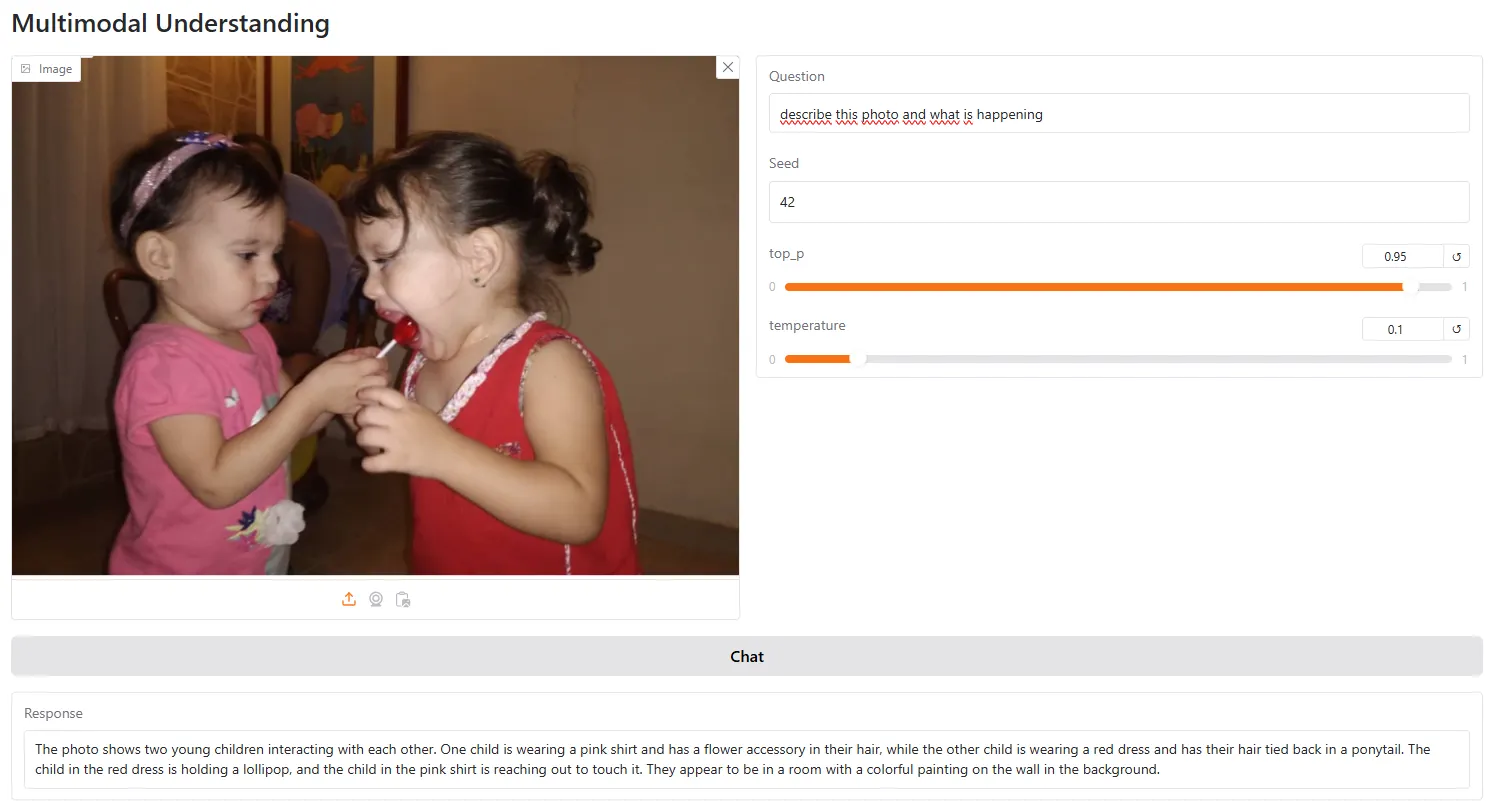
However, it is still not better than the GPT vision, especially for tasks that require logic or some analyzes that exceed what is clearly shown in the picture. For example, we asked the form to analyze this image and explain its message

The model answered: "The image appears to be a comic cartoon depicting a scene where the woman licks the end of a long red tongue associated with a boy."
He ended his analysis by saying that "the general tone of the image appears to be fun and fun, and perhaps a scenario suggests that the woman participates in a harmful or illuminated work."

In these situations where some of the reasons are required beyond a simple description, the model fails most of the time.
On the other hand, Chatgpt, for example, understood the reality inherent in the image: “This metaphor indicates that the positions of the mother, words or values directly affect the child’s actions, especially in a negative way such as bullying or discrimination.” He concluded - and concluded - Painically, we must add.

Its association of its own
The generation of images looks strong and relatively accurate, although it requires a careful demand to achieve good results.
Deepseek claims that Janus Pro Beats SD 1.5, SDXL and Pixart Alpha, but it is important to emphasize that this should be compared to unlimited rule models.
In other words, the fair comparison is among the worst versions of the models currently available, because, it can be said that no one uses the SD 1.5 base to generate art when there are hundreds of fine melodies capable of achieving results that can compete even against the state of artistic models such as flow Or stable proliferation 3.5.
Therefore, generations are not impressive at all in terms of quality, but they seem better than what SD1.5 or SDXL uses out when launch.
For example, here is a face -to -face comparison of the images created by Janus and SDXL to claim: A nice and wonderful baby fox with large brown eyes, autumn leaves in the background, immortal, thin, petals, petals, fairy, very detailed, realistic, cinematic, and natural.

Janus outperforms SDXL in understanding the basic concept: a baby fox can be born instead of a mature fox, as in the case of SDXL.
It also understood the realistic method better, and other elements (thin, cinematic) were also present.
However, SDXL created a fragile image despite the lack of commitment to the claim. The total quality is better, the eyes are realistic, and the details are easier to define.
This style was consistent in other generations: an immediate understanding but bad implementation, with blurry images that feel outdated given the quality of modern photo generators.
However, it is important to note that Janus is the multimedia LLM capable of creating text conversations, analyzing pictures, and generating them as well. Flux, SDXL, and other models are not designed for these tasks.
So, Janus is more diverse in its essence - not great in anything compared to specialized models that excel on a specific mission.
Being an open source, the future of Yanos as a leader among the fans of the IQ of the Wooily depends on a large number of updates that seek to improve these points.
Edit Josh Ketner and Sebastian Senkler
Smart in general Newsletter
Weekly journey narrated GEN, AI Tawylidi model.
Source link